💦 clive: distributed spreadsheets of code+data
On a journey of self-pity and self-indulgence, I have spent the last 5+
years obsessing about how to improve productivity and comfort for software
and reliability engineering. I have explored systems like git or Nix,
various distributed stores, artifact repositories,
build/test/package/deployment systems for a variety of languages. I built,
maintained and/or operated dozens of tools and infrastructure components,
built a distributed CI for distributed systems & a monorepo
environment with IDE and cloud integration. This is the one pragmatic step
I could conceive to jump-start a revolution in the user experience of
technology workers: a solid, scalable, distributed architecture for
spreadsheets of code+data.
Platform
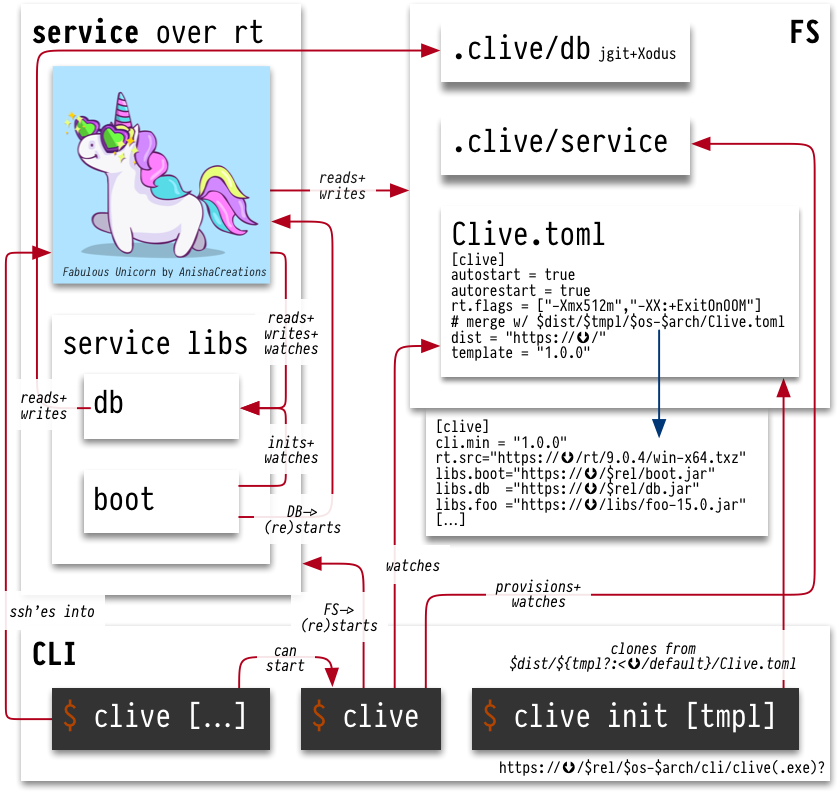
A ❤Nix-like system turned reactive
and implemented through a launcher/manager/client CLI (Go) and a service
(JVM).
Mostly Kotlin instead of the Nix language and a tall layer of C++.
jgit on top of
Xodus as an object and
“filesystem” store, instead of the Nix store on top of the POSIX
filesystem.
Live reactions instead of individual derivations.
High-level abstractions for code generation, builds, tests, assets
pipelines, service and task execution, deployments, etc.
SSH-based communication with Git-based data propagation. Maximized
interoperability with IntelliJ IDEA.
Steps to self-hosting
-
Implement all the non-unicorn bits in the architecture diagram. Now
everything happens in Kotlin.
-
Implement a self-reproducing unicorn. Now we have a living and breathing
dev toolchain unicorn.
-
Evolve the unicorn so it can build and publish the non-unicorn bits. Now
anybody can adopt a baby unicorn and live a harmonious relationship.
Unicorn design draft
Everything that follows needs rewriting over better-defined abstractions.
Abstractions and their layering are emerging as follow:
- A Git over Xodus database.
- On top, auto-reloading classloader, w/ precise invalidation tracking
(not yet loaded ⇒ no reload, possibly in-place bytecode replacements).
- A functional object model, fully serializable and persistable in the database
using Kryo, where entities can exist and evolve as references.
Entities are maintained by arbitrary code through Git references and can contain
full object graphs which can refer to other live references. Some references
propagate their changes back to any consuming code.
The full Git reference store is ACID.
In that functional project model:
- Trust/delegation models using SSH keypairs.
- On top of said trust/delegation model, an execution dispatch model across services,
including through P2P / clusters / cloud providers or config GUIs on laptops.
- A distributed execution engine, which continuously rebuilds parts of the model
as changes to their inputs are progatated.
Amongst other tasks, that execution engine could, for example:
- Start and stop other execution engines from anywhere in any DB over time,
including as the result of tasks from other models,
- Watch local filesystems and propagate changes into the object model,
- Stream parts of the object model back to local filesystems,
or various external services as they change,
- Run arbitrary services, recurring tasks, etc.
Click to reveal outdated notes
What I think an adult unicorn looks like
Peaceful, specialized, living in big nerds bound in harmony by
functional dynamic networks of trust
-
Clive is a distributed ecosystem of expressions for a Redux-like
architecture (where the resolvers are replaced with Kotlin code built
on top of layers of higher-and-higher level APIs) + React-like
architecture (where the virtual DOM is replaced with Git objects and
trees). After bootstrapping or seeding from an existing workspace, one
drives and they feed each other. During those reaction chains, both
arbitrary computations (such as code generation, compilation,
packaging, code relocation, arbitrary execution all interleaved for
environments like TypeScript where needed type definitions pour in and
compilation doesn't depend on the source code itself) and their
results can be cached, persisted and distributed programmatically.
-
Any directory with a
Clive.toml becomes a Clive
workspace. A living and breathing workspace started by a simple
command line tool with zero dependencies, maybe from a
$vcs clone to start from and alongside which to co-exist
(with a simple ignore .clive/ as required integration).
-
In that workspace, remote and local code and data materialize by
purpose; they can be modified, replaced and fetched, evaluated,
propagated on the fly. For example one might want to start modifying
just a couple of files in a published module, or fully replace it with
a local checkout. Maybe they'd rather like to read some pre-built
version from their vendor's store. Arbitrary local checkouts,
arbitrarily attached to the workspace, can be manipulated with tools
like version control systems,
git included, without any
disruption to the platform's live operation.
-
As anything changes, whether the current list of targets for the
service (live-deploy this backend, run all the client tests against a
local copy of this backend, etc.) or any of their transitive source
materials (including local files monitored on the fly), all the
corresponding state derivations and side-effects can be applied as
fast possible, either by reading a local or remote cache (
git
over HTTPS and/or SSH), or by computing locally or remotely (remote
Clive instance over HTTPS or SSH), from a long-lived service with hot
caches and through long-lived connections and Git sessions.
-
The end result is soft-real-time code generation, builds, tests,
publishing of artifacts, restarts of services in one's local debugger
or development cluster, etc., from any change to some file on one's
laptop, either offline or through a cloud worker, all within seconds
for most small changes.
-
What's more, the full history of the workspace is recorded into
sessions. Check out any point in time in a session and the full state
might be ready in the local cache: the IDE instantly sees all its
config, the generated code, compiled classes, fetched remote
dependencies, pre-built
node_modules
hierarchies, failed compilations and test results as fast as the
service can copy from this hot Git repository to its local filesystem.
-
A full history of developer sessions would be valuable as a cloud
service; whenever the service on their laptop connects to the
Internet, it automatically pushes all state transitions including file
saves, streaming live when possible. This starting point would be
quite close to the beginnings of real-time continuous integration and
continuous deployment as a service. Secrets management, including for
cloud clusters, would be one the interesting problems to address
through Clive's highly dynamic nature.
-
Every workspace has an SSH private key associated with it in its VFS.
This is a key starting point for most of the clustering and
peer-to-peer networking functionality. That private SSH key could come
from your Unix user, or derived from a config option in the VFS. It
starts propagating into your developer session, and can spread to
copies you personally trust. More keys can easily be inserted into the
VFS through arbitrary logic which lets reactors maintain a set of
active credentials on the fly for the systems which they access. At
the networking level, those workspace SSH keys work to authenticate
both clients and servers. But the trust delegation model is fully
dynamic and the tricks for peer-to-peer don't satisfy all requirements
for an enterprise setup today. For those environments, trust of
GithHub Enterprise's SSH host key when fetching from repositories
there can be provisioned, eg through shared plugin configuration in
workspaces, and architectured around VFS derivation rule expressions.
This incredible level of flexibility combined with strong conventions
throughout the standard modules are the key to a secure distributed
platform, where solid patterns for authentication and role delegation
allow for fine-grained access control policies, a should-have for a
professional tooling platform but unfortunately lacking today.
Inside most unicorns
-
A VFS reactor configured dynamically from the project reactor, hence
fully programmatic, but with amongst other native features:
-
Live writeback to the filesystem (mostly in
.clive subtrees),
-
Live ingest from the filesystem (excludes
.clive everywhere),
-
A mount-point system so a session could easily mount from a local
copy of a module rather point to a remote and vice-versa,
-
Overlay mounts, to override small parts of external projects for
example;
-
A project reactor hooked to the VFS reactor with:
-
Live modelization of the full project model in a single timeline;
-
Functional model for the project, persisted as an immutable
input-addressible object graph, LRU-persisted in the DB;
-
A set of components to materialize the functional model into a
filesystem, eg:
- Remote artifact fetchers,
- Code generators,
- Compilers,
- IDE configuration generator,
- Test executors,
- Service runners;
-
“Targets” in the project functional model tracked as “alive” to
drive execution of components, eg:
- Keep all generated code up-to-date for the IDE,
-
Run client tests against the latest version of services,
- Live-deploy the last tested server to my cloud stack,
-
On the cloud worker for
master, live-publish
static assets to S3 and invalidate CDN caches in
soft-realtime;
-
Powerful distribution models for the execution of some or all of
those components, eg:
-
Only run those tasks when a device is running on sector or is
disconnected, otherwise distribute it to a local cloud of
workers,
-
From those, forward builds requiring a Mac operating system to
a separate cluster of workers (useful to build iOS apps or
Node native modules for example);
-
Pretty strict conventions throughout, eg maximizing out-of-the-box
integration in IDEA, mostly through config auto-generation within
the Clive service rather than through an IDEA plugin, and
carefully optimized behaviours as
clive.kt is
iterated on (including very eager dynamic mounting of
import paths in the VFS, which can help with
autocomplete and offering error checking instantly in IDEs and
live service state views).
-
An SSH server offering a
git-like interface, extended
with session management;
-
An web server offering a rich UI, session management, a session
browser and controller;
-
For clustered environments,
Atomix-based coordination for
parts of the VFS reactions.
Example of model declaration code: /demo/server/clive.kt
// We parse imports to figure out which modules to bring in the classpath.
// For example this loads /thirdParty/clive.kt (or /thirdParty/ratpack/clive.kt if it exists)
import clive.model.jvm.artifacts.docker
import clive.model.jvm.artifacts.macosApp
import clive.model.jvm.artifacts.windowsSelfExtract
import clive.model.jvm.Dependencies
import clive.model.jvm.JVM
import clive.model.jvm.JVMArgs
import clive.model.kotlin.backendModule
import thirdParty.ratpack
backendModule {
dependencies = Dependencies {
compile {
ratpack.classes
}
runtime {
ratpack.transitive.exclude { thirdParty.hadoop }
}
}
jvm = JVM {
args = JVMArgs {
memory = 16.GB
}
}
artifacts = Artifacts {
docker
windowsSelfExtract
macosApp(jvm = this@backendModule.jvm.copy(provider = JVM.Provider.Oracle))
}
}
